Before talking about what is Hadoop?, it is important for you to know why the need for Big Data Hadoop came up and why our legacy systems weren’t able to cope up with big data. Let’s learn about Hadoop first in this Hadoop tutorial.
While learning ‘What is Hadoop?’, we will have to focus on the following topics:
While learning ‘What is Hadoop?’, we will have to focus on the following topics:
- Problems with Legacy Systems
- Differences Between Legacy Systems and Big Data Hadoop
- What is Hadoop?
- History of Apache Hadoop
- How did Hadoop solve the problem of Big Data?
- How did Uber deal with Big Data?
- Identification of Big Data at Uber
- Introduction of Apache Hadoop in Uber’s System
- Features of Hadoop
- Various Domains That Use Hadoop
Problems with Legacy Systems
Let us talk about the legacy systems first in this Hadoop tutorial and how they weren’t able to handle big data. But wait, what are legacy systems? Legacy systems are the traditional systems that are old and obsolete due to some issues.
Why do we need big data solutions like Hadoop? Why legacy database solutions like MySQL or Oracle are not feasible options now?
First of all, there is a problem of scalability when the data volume increases in terms of terabytes. You’ll have to denormalize and pre-aggregate data for faster query execution and, as the data gets bigger, you’ll be forced to make changes in the process in terms of optimizing indexes that queries extra.
Why do we need big data solutions like Hadoop? Why legacy database solutions like MySQL or Oracle are not feasible options now?
First of all, there is a problem of scalability when the data volume increases in terms of terabytes. You’ll have to denormalize and pre-aggregate data for faster query execution and, as the data gets bigger, you’ll be forced to make changes in the process in terms of optimizing indexes that queries extra.
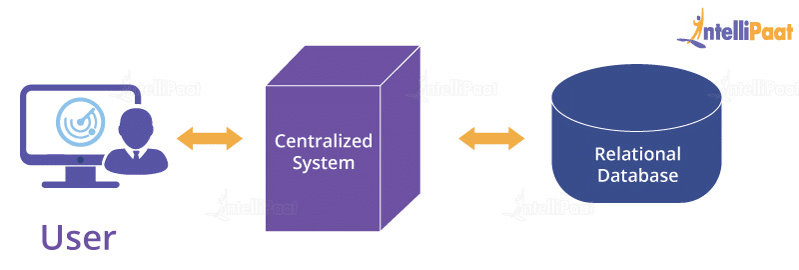
When your database is running with proper hardware resources, yet you see performance issues, then you have to make changes to the query or find a way in which your data can be accessed.
You cannot add more hardware resources or compute nodes and distribute the problem to bring the computation time down, i.e., the database is not horizontally scalable. By adding more resources, you can not hope to improve the execution time or the performance.
The second problem is that a traditional database is designed to process the structured data. Hence, when your data is not in a proper structure, the database will struggle. A database is not a good choice when you have a variety of data in different formats such as text, images, videos, etc.
Another key challenge is that a great enterprise database solution can be quite expensive for a relatively low volume of data, when you add up the hardware costs and the platinum-grade storage costs. In a nutshell, it’s an expensive option.
You cannot add more hardware resources or compute nodes and distribute the problem to bring the computation time down, i.e., the database is not horizontally scalable. By adding more resources, you can not hope to improve the execution time or the performance.
The second problem is that a traditional database is designed to process the structured data. Hence, when your data is not in a proper structure, the database will struggle. A database is not a good choice when you have a variety of data in different formats such as text, images, videos, etc.
Another key challenge is that a great enterprise database solution can be quite expensive for a relatively low volume of data, when you add up the hardware costs and the platinum-grade storage costs. In a nutshell, it’s an expensive option.
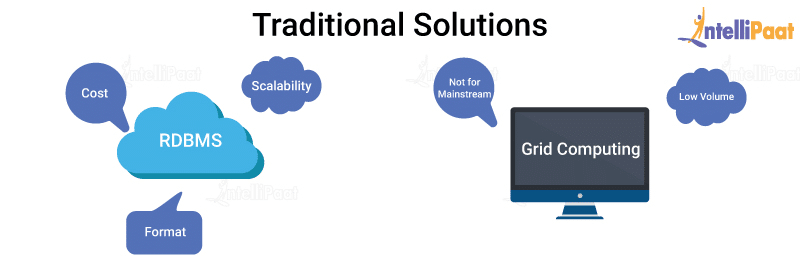
Next, we have the distributed solutions, namely, grid computing, that are basically several nodes operating on a data paddler and hence quicker in computation.
But, for these distributed solutions, there are two challenges:
But, for these distributed solutions, there are two challenges:
- First, high-performance computing is better for computing-intensive tasks that have a comparatively lesser volume of data. So, it doesn’t perform well when the data volume is high.
- Second, grid computing needs good experience with low-level programming knowledge to implement, and hence it wouldn’t fit for the mainstream.
So, basically, a good solution should, of course, handle huge volumes of data and provide efficient data storage, regardless of the varying data formats, without data loss.
Next up in this Hadoop Tutorial, let’s look at the differences between the legacy systems and Big Data Hadoop, and then we will move on to ‘What is Hadoop?’
Differences Between Legacy Systems and Big Data Hadoop
While the traditional databases are good at certain things, Big Data Hadoop is good at many others. Let’s refer the below image:
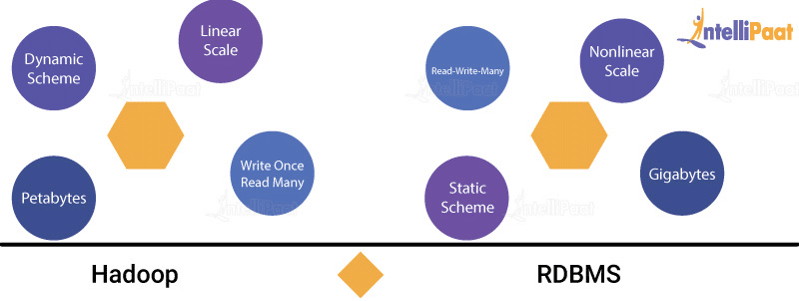
- RDBMS seems to work well with fewer terabytes of data. Whereas, in Hadoop, the volume processed is in petabytes.
- Hadoop can actually work with changing schema, along with that it can support files in various formats. Whereas, when we talk about the RDBMS, it has a schema that is really strict and not so flexible, and it cannot handle multiple formats.
- The database solutions scale vertically, i.e., more resources can be added to a current solution and any improvements in the process—such as, tuning the queries, adding more indexes, etc.—can be made as required. But, they will not scale horizontally. This means, you can’t decrease the execution time or improve the performance of a query by just increasing the number of computers. In other words, you cannot distribute the problem among many nodes.
- The cost for your database solution can get really high pretty quickly when the volume of the data you’re trying to process increases. Whereas, Hadoop provides a cost-effective solution. Hadoop’s infrastructure is based on commodity computers implying that no specialized hardware is required here, hence decreasing the expense.
- Generally, Hadoop is referred to as a batch-processing system, and it is not as interactive as a database. Thus, millisecond response time can’t be expected from Hadoop. But it writes the dataset as an operator and analyzes the data several times, i.e., with hadoop, reading and writing multiple times is possible.
By now, you have got an idea about the differences between Big Data Hadoop and the legacy systems. Let’s come back to the real question now.
What is Hadoop? which is next in this first section of the Hadoop tutorial.
What is Hadoop? which is next in this first section of the Hadoop tutorial.
What is Hadoop?
In this Big Data Hadoop tutorial, our major focus is on ‘What is Hadoop?’
Big Data Hadoop is the best data framework that provides utilities, which help several computers solve queries involving huge volumes of data, e.g., Google Search. It is based on the MapReduce pattern, in which you can distribute a big data problem into various nodes and then consolidate the results of all these nodes into a final result. Big Data Hadoop is written in Java programming language. Because of the robustness of Java, Apache Hadoop ranks among the highest level Apache projects. It is designed to work on a single server with thousands of machines each one providing local computation, along with storage. It supports a huge collection of datasets in a computing environment.
Hadoop is basically licensed under Apache v2 license. It was developed based on a paper presented by Google on the MapReduce system, and hence it applies all the concepts of functional programming.
Since the biggest strength of Apache Hadoop is its scalability, it has upgraded itself from working on a single node to seamlessly handling thousands of nodes, without making any issues.
Hadoop is basically licensed under Apache v2 license. It was developed based on a paper presented by Google on the MapReduce system, and hence it applies all the concepts of functional programming.
Since the biggest strength of Apache Hadoop is its scalability, it has upgraded itself from working on a single node to seamlessly handling thousands of nodes, without making any issues.
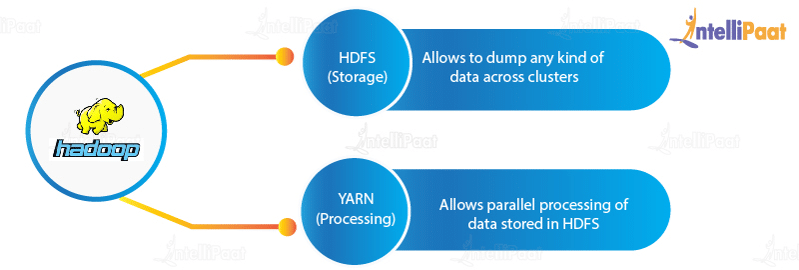
Several domains of Big Data indicate that we are able to handle data in the form of videos, text, images, sensor information, transactional data, social media conversations, financial information, statistical data, forum discussions, search engine queries, e-commerce data, weather reports, news updates, and many more
Big Data Hadoop runs applications on the grounds of MapReduce, wherein the data is processed in parallel, and accomplishes the whole statistical analysis on the huge amount of data.
As you have learned ‘What is Hadoop?,’ you must be interested in learning the history of Apache Hadoop. Let’s see that next in this Hadoop tutorial.
Big Data Hadoop runs applications on the grounds of MapReduce, wherein the data is processed in parallel, and accomplishes the whole statistical analysis on the huge amount of data.
As you have learned ‘What is Hadoop?,’ you must be interested in learning the history of Apache Hadoop. Let’s see that next in this Hadoop tutorial.
History of Apache Hadoop
Doug Cutting—who created Apache Lucene, a popular text search library—was the man behind the creation of Apache Hadoop. Hadoop got introduced in 2002 with Apache Nutch, an open-source web search engine, which was part of the Lucene project.
Now that it is clear to you ‘What is Hadoop?’ and a bit of the history behind it, next up in this tutorial, we will be looking at how Hadoop has actually solved the problem of big data.
Now that it is clear to you ‘What is Hadoop?’ and a bit of the history behind it, next up in this tutorial, we will be looking at how Hadoop has actually solved the problem of big data.
How did Hadoop solve the problem of Big Data?
Since you have already answered the question, ‘What is Hadoop?,’ in this Hadoop tutorial, now you need to understand how it becomes the ideal solution for big data.
The proposed solution for the problem of big data should:
- Implement good recovery strategies
- Be horizontally scalable as data grows
- Be cost-effective
- Minimize the learning curve
- Be easy for programmers and data analysts, and even for non-programmers, to work with
And, this is exactly what Hadoop does!
Hadoop can handle huge volumes of data and store the data efficiently in terms of both storage and computation. Also, it is a good recovery solution for data loss and, most importantly, it can horizontally scale. So, as your data gets bigger, you can add more nodes and everything will work seamlessly.
It’s that simple!
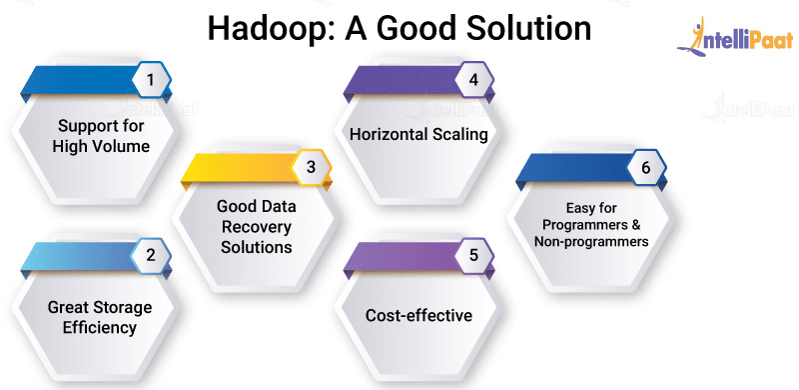
Hadoop is cost-effective as you don’t need any specialized hardware to run it. This makes it a great solution even for startups. Finally, it’s very easy to learn and implement as well.
I hope, now you can answer the question ‘What is Hadoop?’ more confidently.
Let’s now see a use case that can tell you more about Big Data Hadoop.
I hope, now you can answer the question ‘What is Hadoop?’ more confidently.
Let’s now see a use case that can tell you more about Big Data Hadoop.
How did Uber deal with Big Data?
Let’s discuss how Uber managed to fix the problem of 100 petabytes of analytical data generated within its system due to more and more insights over time.
Identification of Big Data at Uber
Before Uber realized the existence of big data within its system, the data used to be stored in legacy database systems, such as MySQL and PostgreSQL, in databases or tables. In the company, the total data size back in 2014 was around a few terabytes. Therefore, the latency of accessing this data was very fast, accomplished in less than a minute!
Here is how Uber’s data storage architecture looked like in the year 2014:
Here is how Uber’s data storage architecture looked like in the year 2014:
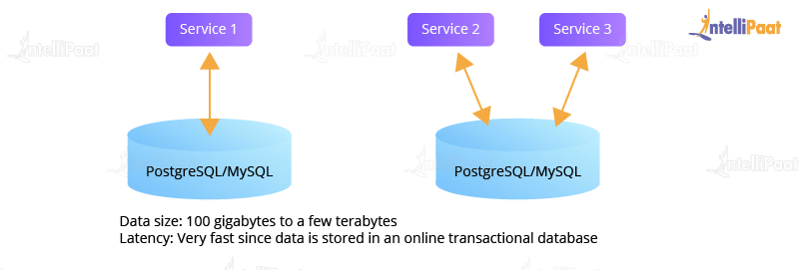
As the business started growing rapidly, the size of the data started increasing exponentially, leading to the creation of an analytical data warehouse that had all the data in one place easily accessible to the analysts all at once. To do so, the data users was categorized into three main groups:
- City Operations Team: On-ground crews responsible for managing and scaling Uber’s transport system.
- Data Scientists and Analysts: A group of Analysts and Data Scientists who need data to deliver a good service regarding transportation.
- Engineering Team: Engineers focused on building automated data applications.
A data warehouse software named Vertica was used as it was fast, scalable, and had a column-oriented design. Besides, multiple ad-hoc ETL jobs were created that copied data from different sources into Vertica. In order to achieve this, Uber started using an online query service that would accept users’ queries based on SQL and upload them on to Vertica.
It was a huge success for Uber when Vertica was launched. Uber’s users had a global view, along with all the data they needed in one place. In just a few months later, the data started increasing exponentially as the number of users was increasing.
Since SQL was in use, the City Operators Team found it easy to interact with whatever data they needed without having any knowledge of the underlying technologies. On the other hand, the Engineering Team began building services and products according to the user needs that were concluded from the analysis of data.
Since SQL was in use, the City Operators Team found it easy to interact with whatever data they needed without having any knowledge of the underlying technologies. On the other hand, the Engineering Team began building services and products according to the user needs that were concluded from the analysis of data.
Though everything was going well and Uber was attracting more customers and profit, there were still a few limitations:
- The use of data warehouse became too expensive as the data compilation had to be extended to involve more and more data. So, to free up more space for new data, older and obsolete data had to be deleted.
- Uber’s Big Data platform wasn’t scalable horizontally. Its prime goal was to focus on the critical business needs for centralized data access.
- Uber’s data warehouse was used like a data lake where all data were piled up, even multiple copies of the same data, that increased the storage costs.
- When it came to data quality, there were issues related to backfilling as it was laborious and time-consuming and the ad-hoc ETL jobs were source-dependant. Data projections and data transformations were performed during the time of ingestion and, due to the lack of standardized ingestion jobs, it became difficult to ingest new
Introduction of Apache Hadoop in Uber’s System
To address the problems created by big data, Uber took the initiative to re-architecture its Big Data platform on top of Hadoop. In other words, it designed an Apache Hadoop data lake and ingested all the raw data from various online data stores into it once, without any transformation during this process. The change in the design decreased the data load on its online data stores and helped it to shift from the ad-hoc ingestion jobs to an ingestion platform that was scalable.

Then, Uber introduced a series of innovations, such as Presto, Apache Spark, and Apache Hive to enable interactive user queries and access to data and to serve even larger queries, all making Uber’s Big Data platform more flexible.
Data modeling and transformation were needed to make the platform scalable which was held only in Apache Hadoop. This enables quick data recovery when there were any issues.
Another thing that really helped Uber was that it made sure only modeled tables to be transferred onto its warehouse. This, in turn, reduced the operational cost for running a large data warehouse. This was termed as the second generation Uber’s Big Data platform.
Now, the ad-hoc data ingestion jobs were exchanged with the standard platform in order to transfer all the data in the original and nested formats into the Hadoop lake.
Another thing that really helped Uber was that it made sure only modeled tables to be transferred onto its warehouse. This, in turn, reduced the operational cost for running a large data warehouse. This was termed as the second generation Uber’s Big Data platform.
Now, the ad-hoc data ingestion jobs were exchanged with the standard platform in order to transfer all the data in the original and nested formats into the Hadoop lake.
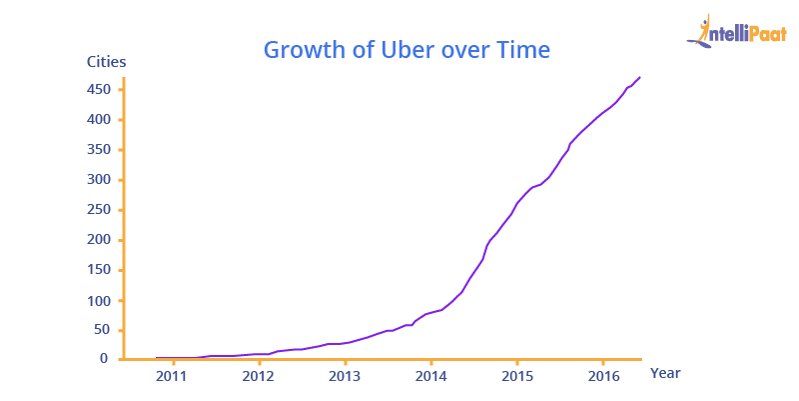
As Uber’s business was growing at the speed of light, tens of terabytes of data got generated and added to the Hadoop data lake, on a daily basis. Soon, its Big Data platform grew over 10,000 vCores having approximately 100,000 batch jobs running per day. This resulted in the Hadoop data lake becoming a centralized source-of-truth for Uber’s analytical data.
This is how Uber managed its big data with the help of Hadoop ecosystem.
The question ‘What is Hadoop?’ cannot be answered completely without discussing about its features. So, let’s move on with that now in this Hadoop Tutorial.
Features of Hadoop
Let’s now look at a few features of Big Data Hadoop:
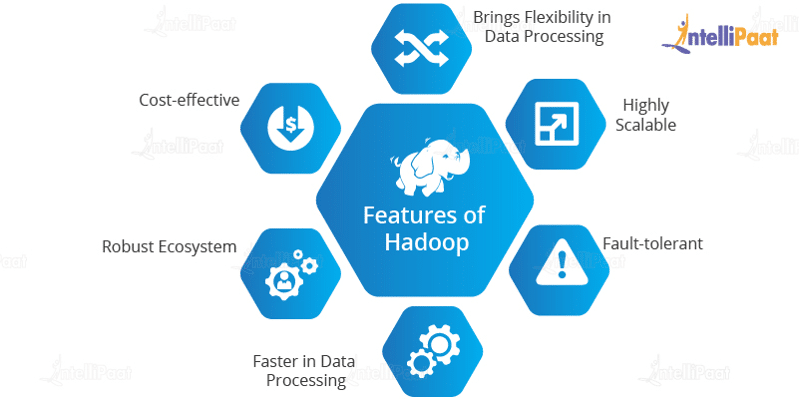
1. Enables Flexible Data Processing
The most prominent problem organizations face is the issue of handling unstructured data. Hadoop plays a key role here as it is able to manage data, whether it is structured or unstructured, or of any kind.
The most prominent problem organizations face is the issue of handling unstructured data. Hadoop plays a key role here as it is able to manage data, whether it is structured or unstructured, or of any kind.
2. Highly Scalable
Since Hadoop is an open-source platform that runs on proper industry-standard hardware, it makes it a highly scalable platform wherein distinct nodes can easily be united in the system for making replicas of data blocks.
Since Hadoop is an open-source platform that runs on proper industry-standard hardware, it makes it a highly scalable platform wherein distinct nodes can easily be united in the system for making replicas of data blocks.
3. Fault-tolerant
In Hadoop, data is actually saved in HDFS wherein it can automatically be duplicated at three different locations. Therefore, even if two of the systems get collapsed, the file will still be present on the third system.
In Hadoop, data is actually saved in HDFS wherein it can automatically be duplicated at three different locations. Therefore, even if two of the systems get collapsed, the file will still be present on the third system.
4. Faster in Data Processing
Hadoop is remarkably efficient at batch processing at high volume. This is because Hadoop can perform parallel processing. It can implement batch processes 10 times quicker when compared to a single thread server or mainframe.
Hadoop is remarkably efficient at batch processing at high volume. This is because Hadoop can perform parallel processing. It can implement batch processes 10 times quicker when compared to a single thread server or mainframe.
5. Robust Ecosystem
Hadoop has a pretty robust ecosystem which suitably aligns with the analytical requirements of developers and small or large organizations.
Hadoop has a pretty robust ecosystem which suitably aligns with the analytical requirements of developers and small or large organizations.
6. Cost-effective
There are a lot of cost benefits that Hadoop brings in. Parallel computing to commodity servers result in a noticeable reduction in the cost per terabyte of storage.
There are a lot of cost benefits that Hadoop brings in. Parallel computing to commodity servers result in a noticeable reduction in the cost per terabyte of storage.
Next in this Hadoop tutorial, let’s now look at the various domains used in Hadoop.
Various Domains That Use Hadoop
Hadoop is being used in a large number of sectors to manage data effectively. Some of these major domains are as follows:
- Banking
Banks have a huge amount of data stored in their servers and databases that needs to be managed effectively and to be secured at the same time. Meanwhile, they have to adhere to customer requirements and reduce risks, along with sustaining regulatory compliance.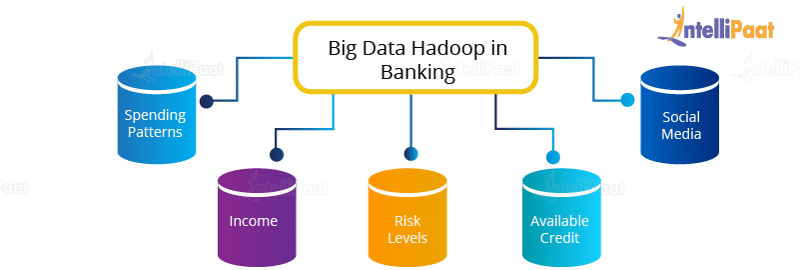 How does Hadoop pitch in?
How does Hadoop pitch in?
Vast financial data residing in the extensive databases of banking sectors can be converted into a goldmine of information provided that there is a suitable tool to analyse data, for example, Cloudera. - Government
Government sectors mainly utilize big data in managing their huge stack of resources and utilities, along with getting insights from surveys conducted on a huge scale. They need to manage huge databases containing the data records of billions of people.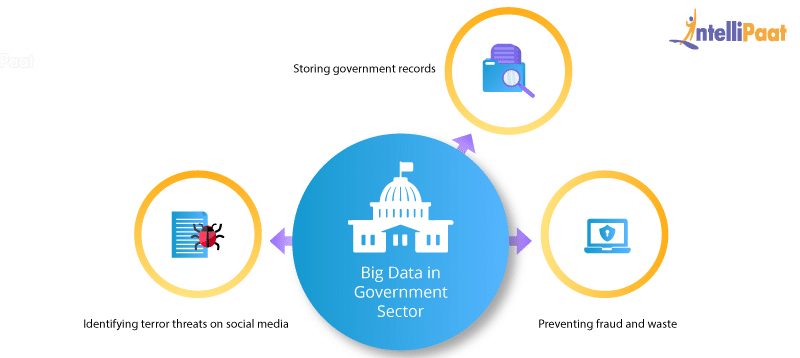 How does Hadoop cater to this problem?
How does Hadoop cater to this problem?- Preventing fraud and waste: Apache Hadoop is a tool that can be used to detect fraud and analyze data by creating new data models focused on fraud, waste, and abuse.
- Identifying terror threats on social media: Terrorist organizations often communicate through social networks in order to circulate instructions. Hadoop not only identifies such data but with its advanced filtering and matching algorithms it can be used to detect all the accomplices working with such organizations.
- Storing government records: It’s hard to store extensive amounts of data—e.g., the data records related to Aadhar card—in traditional databases. Thus, the government is using various Big Data Analytics tools, especially Hadoop, to sort and manage such huge data effectively and efficiently.
- Education
The education sector has to maintain a huge volume of data that may be segregated into several fields. To manage this data and to provide access to it according to users’ interests is a huge challenge.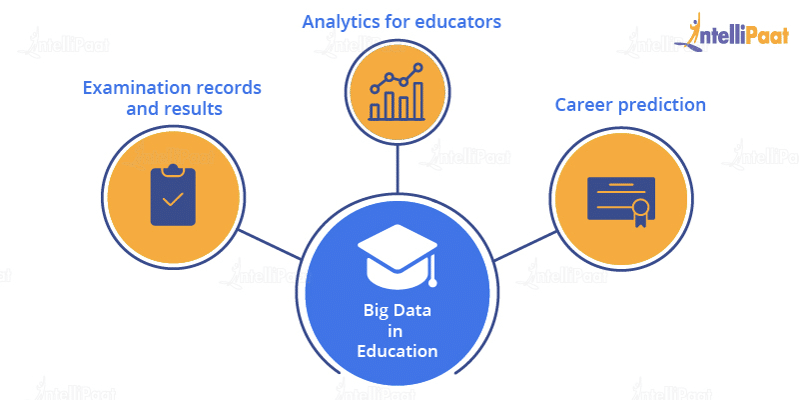 How is Hadoop used in the education sector?
How is Hadoop used in the education sector?- Examination records and results: Analyzing each students result to get a better understanding of the student’s behavior and thus creating the best possible learning environment
- Analytics for educators: Many programs can be created encouraging individuals about their interests. And, on this basis, many reports can be created. And accordingly, educators can be assigned with their respective skills and interests.
- Career prediction: A thorough analysis of a student’s report card. This analysis can be done using various Hadoop tools and can suggest some appropriate courses a student can pursue in the future according to his/her areas of interest.
- HealthcareDue to a large population, it gets increasingly difficult managing all medical-related data in the healthcare sector and analyzing the data to suggest a suitable treatment for each of the patients. Several Machine Learning algorithms and Data Analytics tools can be used for analyzing patients’ medical history and getting insights from it and thus, in turn, appropriately treating them.
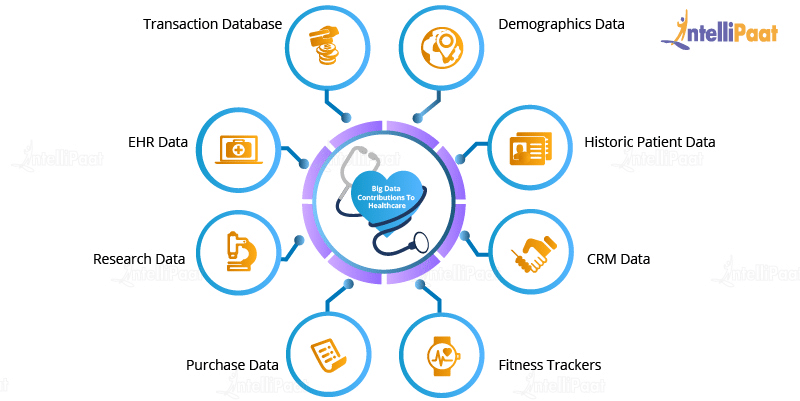 Use cases of Big Data Hadoop in the Healthcare Sector
Use cases of Big Data Hadoop in the Healthcare Sector- Prediction analytics in healthcare: Several Big Data tools are available to analyze and assess patients’ medical history and give a predictive measure as to what kind of treatment can be used to cure them in the future.
- Electronic health records: Electronic health records have become one of the main applications of big data in healthcare as they enable every patient to possess his/her own medical records such as prescribed medicines, medical reports, lab test results, etc. This data can be modified over time by doctors and shared efficiently.
- E-commerceE-commerce tools can help provide insights into what a customer needs and the current requirements of the market. These tools can also help enterprises in building customer relationships and new strategies and ideas as to how to expand their business further.
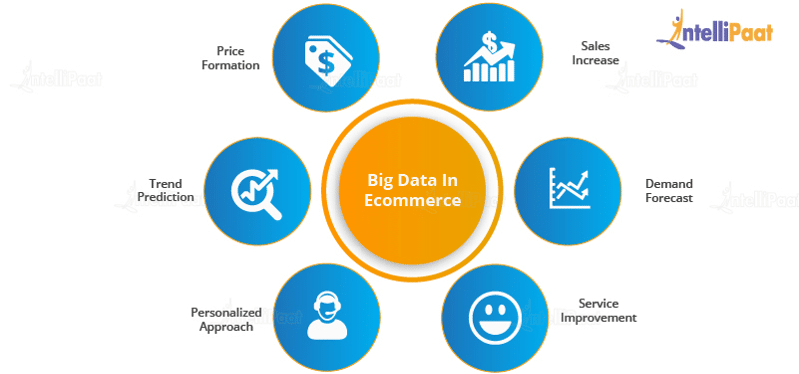
- Service Improvement: Various Big Data tools can analyze demands in the market, along with predicting what customers would want more in the future based on these insights.
- Personalized Approach: This involves sending selective mails and offers to customers who are interested in a particular domain.
Price Formation: For analyzing the dynamic nature of the market and the demand-and-supply ratio and for predicting the pricing of a particular product, various tools can be used so that the sale of this product does not get affected.
- Social media
Social media today is the largest data producer, and it contains a lot of sensitive data that needs to be managed efficiently and securely. This data also needs to be optimized and stored effectively.
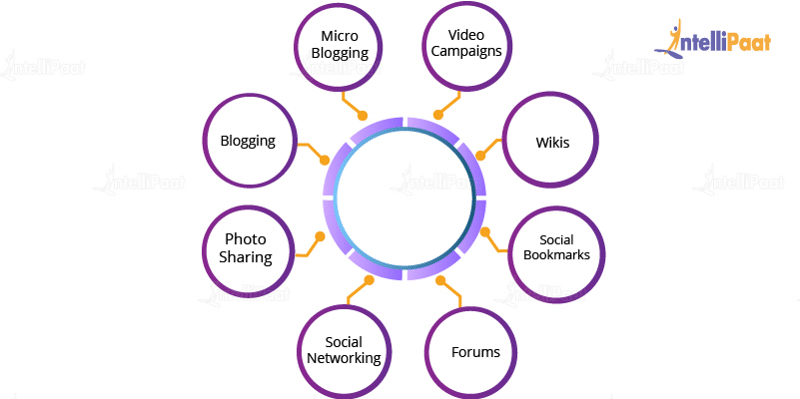
Usage of Big Data Tools in Social Media
- Bitly: Bitly is a Data Analytics tool used for high-quality analytics, and it is able to establish short links that can be tracked across the web. It can be used to cut short any URL so that it can fit nicely across any social media webpage.
- Everypost: Everypost is a platform that can manage multiple networks in parallel. Here, a user can curate a type of content at one place and organize it in another. It enables the storage of massive data on various social websites in a single large repository.
We have now come to the end of this section on ‘What is Hadoop?’
In this section of the Hadoop tutorial, we learned ‘What is Hadoop?’, the need for it, and how Hadoop solved the problem of big data, and we also saw how Uber dealt with its big data with the help of the Hadoop ecosystem.
In this section of the Hadoop tutorial, we learned ‘What is Hadoop?’, the need for it, and how Hadoop solved the problem of big data, and we also saw how Uber dealt with its big data with the help of the Hadoop ecosystem.
What is Hadoop? To answer this question comprehensively, we need to know the about Big Data. What is this Big Data that we are talking about all this while in this tutorial? So, in the next section of this Big Data Hadoop tutorial, we shall be learning about What is Big Data.
Recommended Audience
- Intellipaat’s Hadoop tutorial is designed for Programming Developers and System Administrators
- Project Managers eager to learn new techniques of maintaining large datasets
- Experienced working professionals aiming to become Big Data Analysts
- Mainframe Professionals, Architects & Testing Professionals
- Entry-level programmers and working professionals in Java, Python, C++, eager to learn the latest Big Data technology.
Prerequisites
- Before starting with this Hadoop tutorial, it is advised to have prior programming language experience in Java and Linux Operating system.
- Basic command knowledge of UNIX and SQL Scripting can be beneficial to better understand the Big data concepts in Hadoop applications.
No comments:
Post a Comment