Hadoop File System was mainly developed for using distributed file system design. It is highly fault tolerant and holds huge amount of data sets and provides ease of access. The files are stored across multiple machines in a systematic order. These stored files are stored to eliminate all possible data losses in case of failure and helps make applications available for parallel processing. This file System is designed for storing very large amount of files with streaming data access.

HDFS is based on the Google File System (GFS) and written completely in Java programming language. Google provided only a white paper, without any implementation. Around 90 percent of the GFS architecture has been implementation in the form of HDFS.
HDFS was originally built and developed as a storage infrastructure for the Apache Nutch web search engine project. It was initially known as the Nutch Distributed File System (NDFS).
Assumptions and Goals
Hardware Failure
Hardware failure is basically the norm instead of exception. An HDFS instance consists of hundreds or thousands of server machines, each consuming the storing part of the file system’s data. The real fact is that there are a large number of components and that each component consists of non-trivial probability of failure which explains that some of the component of HDFS is always non-functional. Therefore, detection of faults is quick, automatic recovery from them is the main core architectural motto of HDFS.
Streaming Data Access
Applications that run on HDFS need streaming access to every individual data set. They are not meant for general purpose applications that typically run on general purpose file systems. HDFS is designed more for batch processing instead of interactive use by End-users. The emphasis is on high streams throughput of data access rather than low latency of data access. POSIX consists of many hard requirements which are not required for applications which come under HDFS. POSIX semantics are trending huge success in certain key areas to increase data throughput rates.
Large Data Sets
Applications that run on HDFS have massively large data sets. A typical file in HDFS ranging from gigabytes to terabytes in size. Thus, HDFS are built in such a way that it supports large files. It provides high aggregate data bandwidth and scale measuring hundreds of nodes in a single cluster. It should access to tons of millions of files at a same time.
Simple Coherency Model
HDFS applications need write-once-read-many access model for files. A file once created, written, and closed need not be changed later. This assumption helps to simplify the data coherency issues and enables us the high throughput data access. A MapReduce application or a web crawler application is perfectly fitted in this model. In future new innovative ideas been implemented to support appending-writes to files in the future.
“Moving Computation is Cheaper than Moving Data”
A computation requested by an application is very more efficient when executed near its operated data. This is termed true when there is huge amount data set. This results in minimization of network congestion and increases the overall throughput of the system. The assumption will implies better if you migrate the computation to the closer data location rather than moving the data to where the application is running. HDFS provides interfaces for applications to move closely among themselves where exactly the data is being located.
Portability across Heterogeneous Hardware and Software Platforms
HDFS has been designed in such a way for easy transport from one platform to another. This facilitates of HDFS as a platform of choice for a large set of applications.
Features of HDFS
- Usage of distributed storage and processing.
- Optimization is used for throughput over latency.
- Efficient in reading large files but poor at seek requests for many small ones.
- A command interface to interact with HDFS is provided.
- The built-in servers of data node and name node helps the end users to check the cluster‘s status as per time intervals.
- Streams access the data of file system.
- Authentication of file permissions and authentication are provided.
- Uses replication are used instead of handling disk failures. Each blocks comprises a file storage on several nodes inside the cluster and the HDFS NameNode continuously keep monitoring the reports which are sent by every DataNode to ensure due to failures no block have gone below the desired replication factor. If this this happens then it schedules the addition of another copy within the cluster.
Why HDFS works very well with Big Data?
- HDFS uses the MapReduce method for access to data which is very fast
- It follows a data coherency model that is simple to implement still highly robust and scalable
- Compatible with any kind commodity hardware and operating system processor.
- Economy is been achieved by distributing data and processing on clusters with parallel nodes
- Data is always safe as it is automatically saved in multiple locations for safe secure.
- It provides a JAVA API’s and C language is on the top priority.
- It is easily accessible using a web browser making it highly utilitarian.
HDFS Architecture
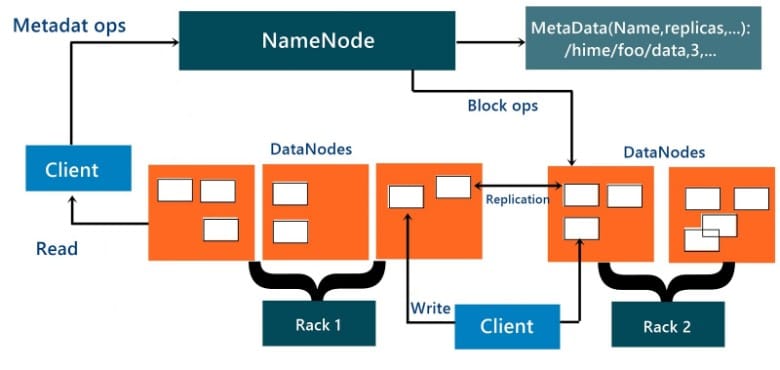
It uses mainly the master slave architecture and contains the following elements:
Namenode and DataNode
The namenode is the commodity hardware that contains the GNU/Linux operating system and its library file setup and the namenode software. The system containing namenode acts as the master server and carries out following tasks:
- Manage namespace for file system.
- Provides client’s access to files.
- Execution of file system operations such as rename, open and close files and directories.
- There are a number of Data Nodes consists of one per node in the cluster, which helps to manage storage attached to the nodes that they run on.
- HDFS exposes a file system namespace and provides access to user data to be stored within files.
- Basically a file is split into one or more blocks and these blocks are stored in a set of DataNodes.
- The NameNode executes file system namespace operations containing opening, closing, and renaming files and directories which determine the mapping of blocks to DataNodes which is responsible for providing read and write requests from the file system’s clients.
- The DataNodes also perform functions such as block creation, deletion, and replication upon instruction from the NameNode.
- These machines typically run a GNU/Linux operating system (OS).
- As we know HDFS is designed and implemented based on Java language; any machine that supports Java application can run the NameNode or the DataNode software.
- HDFS can be deployed on a wide range of machines as the usage of it is highly portable in Java language. A particular deployment has a dedicated machine that runs only the NameNode software. The other machines in the cluster run one instance of the DataNode software only.
- The architecture does not predicate based on running multiple DataNodes on the same machine but in a real deployment that is rarely happened.
The single NameNode in a cluster efficiently simplifies the architecture of the system. The NameNode is the main arbitrator and repository for all HDFS metadata sets. The system is designed in such a way that user data never flows through the NameNode.
Block
Data is mainly stored in HDFS’s file. These files are segregated into one or more segments and further stored in individual data node. These file segments are namely known as block. The default block size is 64MB which can be modified as per the requirements from HDFS configuration.
HDFS blocks are huge compared to disk blocks and the main reason is cost reduction. By making a particular set of block large enough hence here the time consumed to transfer the data from the disk can be made larger than the time to seek from the beginning of the block. Thus the time consumed to transfer a large file made of multiple blocks operates at the disk transfer rate.
HDFS Objectives
- Fault detection and recovery: It provide methods for fast and automatic fault detection and recovery of data.
- Huge datasets: It consists of multiple nodes per cluster to manage the applications with large amount of datasets.
- Hardware at data: HDFS reduces the network traffic and increases the throughput as per the required time intervals.
HDFS High Availability
- HDFS provides features such t recovery is possible in terms of failed namenode by adding support for HDFS high availability (HA).
- A pair of namenodes in an active stands by configuration to take over its duties to continue servicing client requests without any interruption.
The above points can be achieved through following implementations:
- Using highly available shared storage document and to share the edit log.
- Confirming that the DataNodes send block reports to both NameNodes
- Clients must be configured such that it can handle namenode failover
HDFS File Permissions
HDFS has a permissions model accessing the files and directories.
There are three types of permission:
- Read permission (r)
- Write permission (w)
- Execute permission (x)
- The read permission is used to read files or list the contents of files of a directory.
- The write permission is used to write a file, or for a directory, to create or delete files or directories.
- The execute permission is ignored for a file since we can’t execute a file on HDFS, and for a directory you have to access its children.
- Each file and directory has an owner, a group, and a mode within it.
The mode is given the permissions for the user who is the owner, the permissions is given for the users who are members of the group, and the permissions is given for users who are neither the owners nor members of the group.
Hadoop Ecosystem
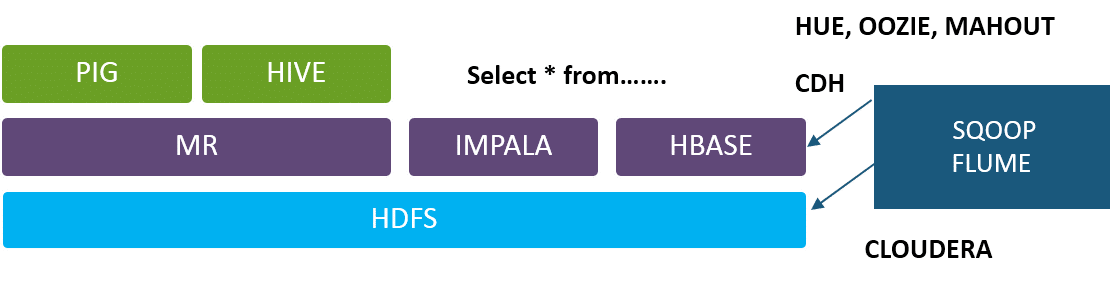
- HDFS is the file system of Hadoop
- MR is the job which runs basically on file system
- The MR Job guide the user to ask question from HDFS files
- Pig and Hive are two projects built so that you can replace coding based on map reduce.
- Pig and Hive interpreter converts the script and SQL queries “INTO” MR Job
- To save the document on MapReduce only dependency for querying on HDFS will be Impala and Hive
- Impala Optimized for high latency queries are based on real time applications.
- Hive is optimized for batch processing jobs.
- Sqoop: Can put data from a relation DB to Hadoop ecosystem
- Flume sends the data generated from external system to move towards the HDFS to adapt for high volume logging.
- Hue: Cluster based on Graphical frontend
- Oozie: It is an workflow management tool
- Mahout : Machine learning Library files.
- When a 150 mb file is being implemented forcibly Hadoop ecosystem break itself into multiple parts to achieve parallelism.
- It breaks itself into smaller units where default unit size is 64 mb
- Data node is the demon which takes care of all welfares happening on individual node
- Name node keeps track on all aspects from when and where required and how to collect the same group together.
Consider the following Problems:
- If one of the nodes fails, then the data stored goes missing at that node
- Network Failure issues.
- Single Point of Failure: Name Node which is the Heart of Hadoop ecosystem
Solution:
- Hadoop solves this problem by duplicating each and every data fragment thrice and save it on different nodes, so that even if one node fails, we can still recover the data.
- Network Failure is an important issue as lot of shuffle happens in the day to day activity.
- Name node failure was reduced initially by storing the name node data on NFS (Network file Server) which is been recovered in case of Name node crash.
HDFS Installation and Shell Commands
Setting up of the Hadoop cluster:
Successfully installation of Hadoop and configure them so that the clusters ranging from couple of nodes to even tens of thousands over huge amount of clusters. For this, first you need to install Hadoop on a single machine and it requires compulsory of installing Java if this doesn’t exist in your system.
Getting Hadoop to work on the entire cluster involves required software on all the machines that are tied up with the cluster. As per the norms one of the machines is associated with the Name Node and another associated with the Resource Manager. The other services like The MapReduce Job History and the Web App Proxy Server usually hosted on specific machines or even on shared resources are loaded as per the requirement of the task. Rest all the nodes in cluster have a dual nature of both the Node Manager and the Data Node. These are collectively termed as the slave nodes.
Hadoop to work in the non-secure mode
The Java configuration of Hadoop has two important files:
Successfully installation of Hadoop and configure them so that the clusters ranging from couple of nodes to even tens of thousands over huge amount of clusters. For this, first you need to install Hadoop on a single machine and it requires compulsory of installing Java if this doesn’t exist in your system.
Getting Hadoop to work on the entire cluster involves required software on all the machines that are tied up with the cluster. As per the norms one of the machines is associated with the Name Node and another associated with the Resource Manager. The other services like The MapReduce Job History and the Web App Proxy Server usually hosted on specific machines or even on shared resources are loaded as per the requirement of the task. Rest all the nodes in cluster have a dual nature of both the Node Manager and the Data Node. These are collectively termed as the slave nodes.
Hadoop to work in the non-secure mode
The Java configuration of Hadoop has two important files:
- Read-only are the default configuration such as -core-default.xml, hdfs-default.xml, yarn-default.xml and mapred-default.xml.
- Site-specific configuration based on -etc/hadoop/core-site.xml, etc/hadoop/hdfs-site.xml, etc/hadoop/yarn-site.xml and etc/hadoop/mapred-site.xml.
Possible to manage the Hadoop scripts in the bin/ directory distribution, by setting site-specific values by the following storage files etc/hadoop/hadoop-env.sh and etc/hadoop/yarn-env.sh.
For the Hadoop cluster configuration you first create the ecosystem where the Hadoop daemons can execute and also requires the parameters for configuration.
The various daemons of Hadoop Distributed File System are listed below:
For the Hadoop cluster configuration you first create the ecosystem where the Hadoop daemons can execute and also requires the parameters for configuration.
The various daemons of Hadoop Distributed File System are listed below:
- Node Manager
- Resource Manager
- WebApp Proxy
- NameNode
- Secondary NameNode
- DataNode
- YARN daemons
The Hadoop Daemons configuration environment
To get the Hadoop daemons’ access the right site with specific customization where the administrators need to use the following commands the etc/hadoop/hadoop-env.sh or the etc/hadoop/mapred-env.sh and etc/hadoop/yarn-env.sh scripts. The JAVA_HOME are specified properly such that it is defined in properly on every remote node.
To get the Hadoop daemons’ access the right site with specific customization where the administrators need to use the following commands the etc/hadoop/hadoop-env.sh or the etc/hadoop/mapred-env.sh and etc/hadoop/yarn-env.sh scripts. The JAVA_HOME are specified properly such that it is defined in properly on every remote node.
Configuration of the individual daemons
The list of Daemons with their relevant environment variable
NameNode –HADOOP_NAMENODE_OPTS
DataNode – HADOOP_DATANODE_OPTS
Secondary NameNode – HADOOP_SECONDARYNAMENODE_OPTS
Resource Manager – YARN_RESOURCEMANAGER_OPTS
Node Manager – YARN_NODEMANAGER_OPTS
WebAppProxy – YARN_PROXYSERVER_OPTS
Map Reduce Job History Server – HADOOP_JOB_HISTORYSERVER_OPTS
Other related important Customization configuration parameters:
NameNode –HADOOP_NAMENODE_OPTS
DataNode – HADOOP_DATANODE_OPTS
Secondary NameNode – HADOOP_SECONDARYNAMENODE_OPTS
Resource Manager – YARN_RESOURCEMANAGER_OPTS
Node Manager – YARN_NODEMANAGER_OPTS
WebAppProxy – YARN_PROXYSERVER_OPTS
Map Reduce Job History Server – HADOOP_JOB_HISTORYSERVER_OPTS
Other related important Customization configuration parameters:
- HADOOP_PID_DIR – the process ID files of the daemons is contained in this directory.
- HADOOP_LOG_DIR – the log files of the daemons are stored in this directory.
- HADOOP_HEAPSIZE / YARN_HEAPSIZE – the heap size is measured in terms of MB’s and if you own an variable that is set to 1000 then automatically the heap is also set to 1000 MB. And by default it is set as 1000
The HDFS Shell Commands
The important operations of Hadoop Distributed File System using the shell commands used for file management in the cluster.
- Directory creation in HDFS for a specific given path are given as.
hadoopfs-mkdir<paths>
Example:
hadoopfs-mkdir/user/saurzcode/dir1/user/saurzcode/dir2
- Listing of the directory contents.
hadoopfs-ls<args>
Example:
hadoopfs-ls/user/saurzcode
- HDFS file Upload/download.
Upload:
hadoopfs -put:
Copy single source file, or multiple source files based on local file system to the Hadoop data file system
hadoopfs-put<localsrc> … <HDFS_dest_Path>
Example:
hadoopfs-put/home/saurzcode/Samplefile.txt/user/saurzcode/dir3/
Download:
hadoopfs -get:
Copies or downloads the files to the local file system
hadoopfs-get<hdfs_src><localdst>
Example:
hadoopfs-get/user/saurzcode/dir3/Samplefile.txt/home/
- Viewing of file content
Same as Unix cat command:
hadoopfs-cat<path[filename]>
Example:
hadoopfs-cat/user/saurzcode/dir1/abc.txt
- File copying from source to destination
hadoopfs-cp<source><dest>
Example:
hadoopfs-cp/user/saurzcode/dir1/abc.txt/user/saurzcode/dir2
- Copying of file to HDFS from a local file and vice-versa
Copy the address from the LocalHost:
hadoopfs-copyFromLocal<localsrc>URI
Example:
hadoopfs-copyFromLocal/home/saurzcode/abc.txt/user/saurzcode/abc.txt
copyToLocal host
Usage:
hadoopfs-copyToLocal [-ignorecrc] [-crc] URI<localdst>
- File moving from source to destination.
But remember, you cannot move files across filesystem.
hadoopfs-mv<src><dest>
Example:
hadoopfs-mv/user/saurzcode/dir1/abc.txt/user/saurzcode/dir2
- File or directory removal in HDFS.
hadoopfs-rm<arg>
Example:
hadoopfs-rm/user/saurzcode/dir1/abc.txt
Repetitive version of delete.
hadoopfs-rmr<arg>
Example:
hadoopfs-rmr/user/saurzcode/
- Showing the file’s final few lines.
hadoopfs-tail<path[filename]>
Example:
hadoopfs-tail/user/saurzcode/dir1/abc.txt
- Showing the aggregate length of a file.
hadoopfs-du<path>
Example:
hadoopfs-du/user/saurzcode/dir1/abc.txt
No comments:
Post a Comment