Apache Hadoop was developed with the goal of having an inexpensive, redundant data store which would enable organizations to leverage Big Data Analytics economically and increase the profitability of the business.
An Hadoop architectural design needs to have several design factors in terms of networking, computing power, and storage. Hadoop provides a reliable, scalable, flexible, and distributed computing Big Data framework.
Let’s first look at the topics we would be discussing in this section, Hadoop architecture, of Hadoop Tutorial:
- Hadoop Architecture
- Hadoop Distributed File System (HDFS)
- MapReduce Layer
- How does Hadoop work?
- How does Yahoo! use Hadoop Architecture?
For you to become an expert in Hadoop, you need to understand each layer present in the Hadoop architecture.
Hadoop follows a master–slave architecture for storing data and data processing. This master–slave architecture has master nodes and slave nodes as shown in the image below:
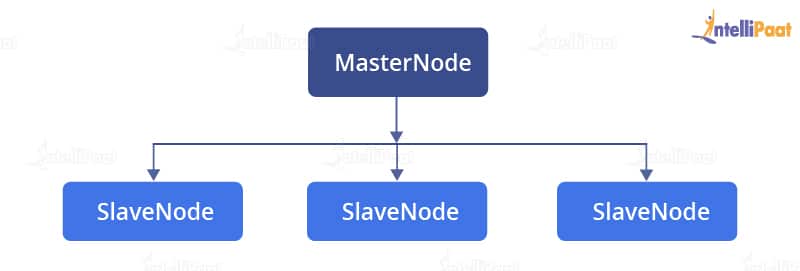
Let’s first look at each terminology before we start with understanding the architecture:
- NameNode: NameNode is basically a master node that acts like a monitor and supervises operations performed by DataNodes.
- Secondary NameNode: A Secondary NameNode plays a vital role in case if there is some technical issue in the NameNode.
- DataNode: DataNode is the slave node that stores all files and processes.
- Mapper: Mapper maps data or files in the DataNodes. It will go to every DataNode and run a particular set of codes or operations in order to get the work done.
- Reducer: While a Mapper runs a code, Reducer is required for getting the result from each Mapper.
- JobTracker: JobTracker is a master node used for getting the location of a file in different DataNodes. It is a very important service in Hadoop as if it goes down, all the running jobs will get halted.
- TaskTracker: TaskTracker is a reference for the JobTracker present in the DataNodes. It accepts different tasks, such as map, reduce, and shuffle operations, from the JobTracker. It is a key player performing the main MapReduce functions.
- Block: Block is a small unit wherein the files are split. It has a default size of 64 MB and can be increased as needed.
- Cluster: Cluster is a set of machines such as DataNodes, NameNodes, Secondary NameNodes, etc.
Here is a rough sketch of the Hadoop architecture:
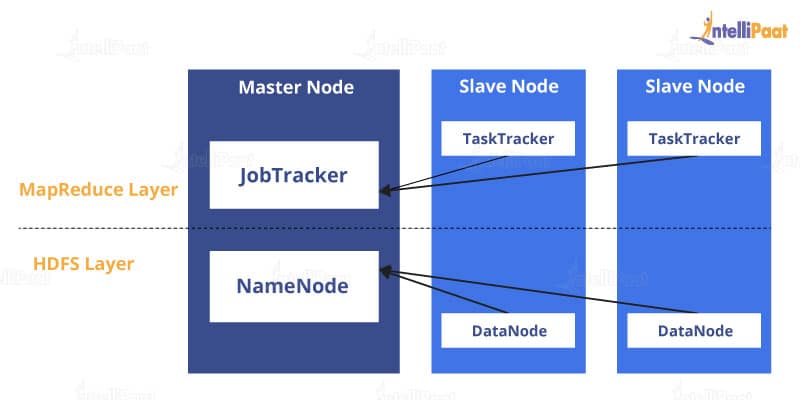
There are two layers in the Hadoop architecture. First, we will see how data is stored in Hadoop and then we will move on to how it is processed. While talking about the storage of files in Hadoop, HDFS comes to place.
Hadoop Distributed File System (HDFS)
HDFS is based on Google File System (GFS) that provides a distributed system particularly designed to run on commodity hardware. The file system has several similarities with the existing distributed file systems. However, HDFS does stand out among all of them.
This is because it is fault-tolerant and is specifically designed for deploying on low-cost hardware.
HDFS is mainly responsible for taking care of the storage parts of Hadoop applications. So, if you have a 100 MB file that needs to be stored in the file system, then in HDFS, this file will be split into chunks, called blocks. The default size of each block in Hadoop 1 is 64 MB, on the other hand in Hadoop 2 it is 128 MB.
HDFS is mainly responsible for taking care of the storage parts of Hadoop applications. So, if you have a 100 MB file that needs to be stored in the file system, then in HDFS, this file will be split into chunks, called blocks. The default size of each block in Hadoop 1 is 64 MB, on the other hand in Hadoop 2 it is 128 MB.
For example, in Hadoop version 1, if we have a 100 MB file, it will be divided into 64 MB stored in one block and 36 MB in another block. Also, each block is given a unique name, i.e., blk_n (n = any number). Each block is uploaded to one DataNode in the cluster. On each of the machines or clusters, there is something called as a daemon or a piece of software that runs in the background.
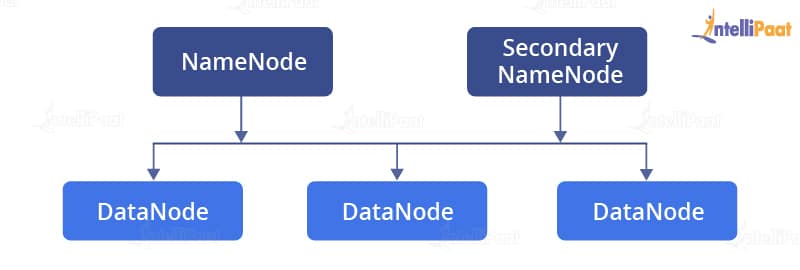
The daemons of HDFS are as follows:
NameNode: It is the master node that maintains or manages all data. It points to DataNodes and retrieves data from them. The file system data is stored on a NameNode.
Secondary NameNode: It is the master node and is responsible for keeping the checkpoints of the file system metadata that is present on the NameNode.
DataNode: DataNodes have the application data that is stored on the servers. It is the slave node that basically has all the data of the files in the form of blocks.
As we know, HDFS stores the application data and the files individually on dedicated servers. The file content is replicated by HDFS on various DataNodes based on the replication factor to assure the authenticity of the data. The DataNode and the NameNode communicate with each other using TCP protocols.
The following prerequisites are required to be satisfied by HDFS for the Hadoop architecture to perform efficiently:
- There must be good network speed in order to manage data transfer.
- Hard drives should have a high throughput.
MapReduce Layer
MapReduce is a patented software framework introduced by Google to support distributed computing on large datasets on clusters of computers.
It is basically an operative programming model that runs in the Hadoop background providing simplicity, scalability, recovery, and speed, including easy solutions for data processing. This MapReduce framework is proficient in processing a tremendous amount of data parallelly on large clusters of computational nodes.
It is basically an operative programming model that runs in the Hadoop background providing simplicity, scalability, recovery, and speed, including easy solutions for data processing. This MapReduce framework is proficient in processing a tremendous amount of data parallelly on large clusters of computational nodes.
MapReduce is a programming model that allows you to process your data across an entire cluster. It basically consists of Mappers and Reducers that are different scripts you write or different functions you might use when writing a MapReduce program.
Mappers have the ability to transform your data in parallel across your computing cluster in a very efficient manner; whereas, Reducers are responsible for aggregating your data together.
Mappers and Reducers put together can be used to solve complex problems.
Mappers and Reducers put together can be used to solve complex problems.
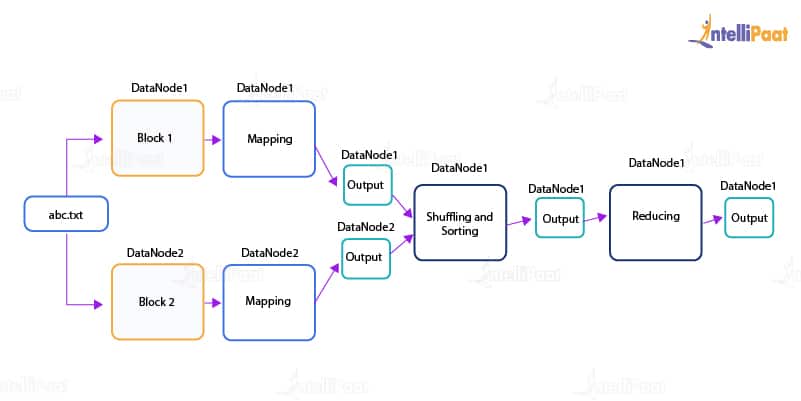
Working of the MapReduce Architecture
The job of MapReduce starts when a client submits a file. The file first goes to the JobTracker. It combines Reduce functions, with the location, for input and output data. When a file is received, the JobTracker sends a request to the NameNode that has the location of the DataNode. The NameNode will send that location to the JobTracker. Next, the JobTracker will go to that location in the DataNode. Then, the JobTracker present in the DataNode sends a request to the select TaskTrackers.
The job of MapReduce starts when a client submits a file. The file first goes to the JobTracker. It combines Reduce functions, with the location, for input and output data. When a file is received, the JobTracker sends a request to the NameNode that has the location of the DataNode. The NameNode will send that location to the JobTracker. Next, the JobTracker will go to that location in the DataNode. Then, the JobTracker present in the DataNode sends a request to the select TaskTrackers.
Next, the processing of the map phase begins. In this phase, the TaskTracker retrieves all the input data. For each record, a map function is invoked, which has been parsed by the ‘InputFormat’ producing key–value pairs in the memory buffer.
Sorting the memory buffer is done next wherein different reducer nodes are sorted by invoking a function called combine. When the map task is completed, the JobTracker gets a notification from the TaskTracker for the same. Once all the TaskTrackers notify the JobTracker, the JobTracker notifies the select TaskTrackers, to begin with the reduce phase.
The TaskTracker’s work now is to read the region files and sort the key–value pairs for each and every key. Lastly, the reduce function is invoked, which collects the combined values into an output file.
How does Hadoop work?
Hadoop runs code across a cluster of computers and performs the following tasks:
- Data is initially divided into files and directories. Files are then divided into consistently sized blocks ranging from 128 MB in Hadoop 2 to 64 MB in Hadoop 1.
- Then, the files are distributed across various cluster nodes for further processing of data.
- The JobTracker starts its scheduling programs on individual nodes.
- Once all the nodes are done with scheduling, the output is returned.
Data from HDFS is consumed through MapReduce applications. HDFS is also responsible for multiple replicas of data blocks that are created along with the distribution of nodes in a cluster, which enables reliable and extremely quick computations.
So, in the first step, the file is divided into blocks and is stored in different DataNodes. If a job request is generated, it is directed to the JobTracker.
So, in the first step, the file is divided into blocks and is stored in different DataNodes. If a job request is generated, it is directed to the JobTracker.
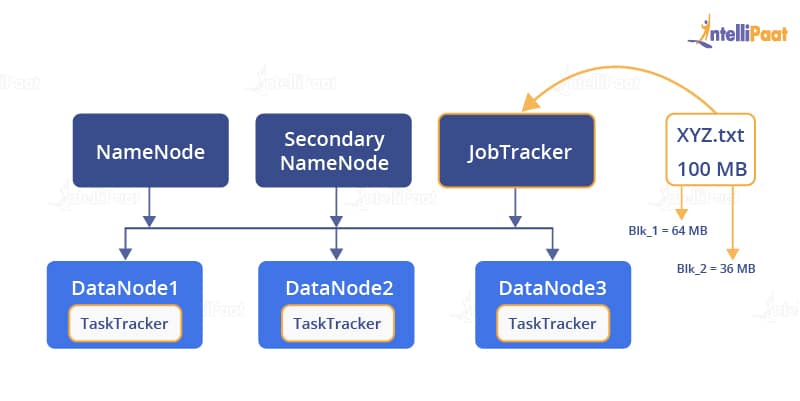
The JobTracker doesn’t really know the location of the file. So, it contacts with the NameNode for this.
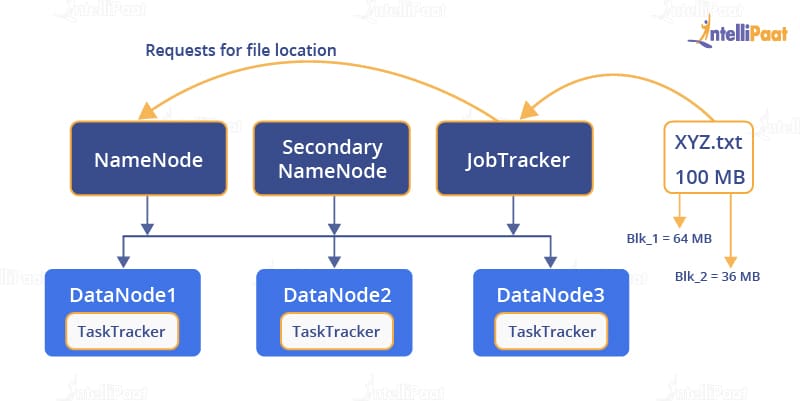
The NameNode will now find the location and give it to the JobTracker for further processing.
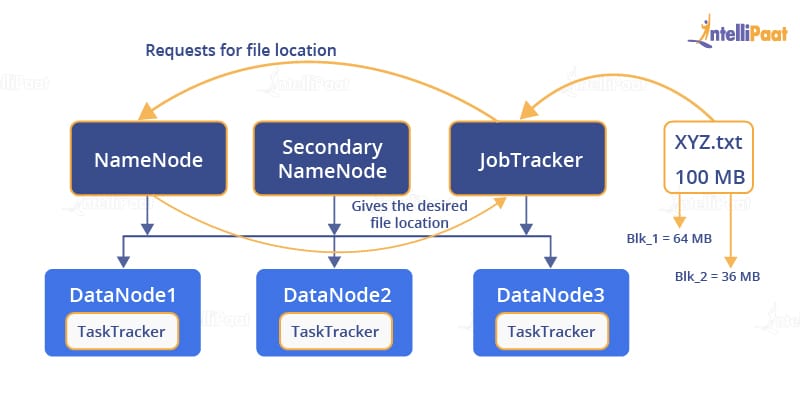
Now, since the JobTracker knows the location of the blocks of the requested file, it will contact the TaskTracker present on a particular DataNode for the data file.
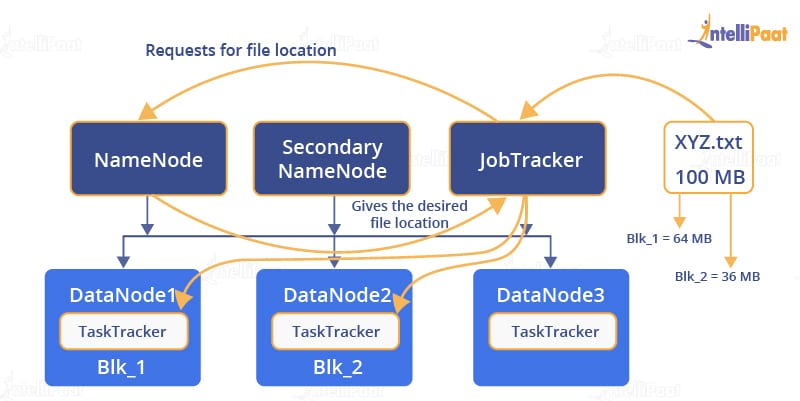
The TaskTracker will now send the data it has to the JobTracker.
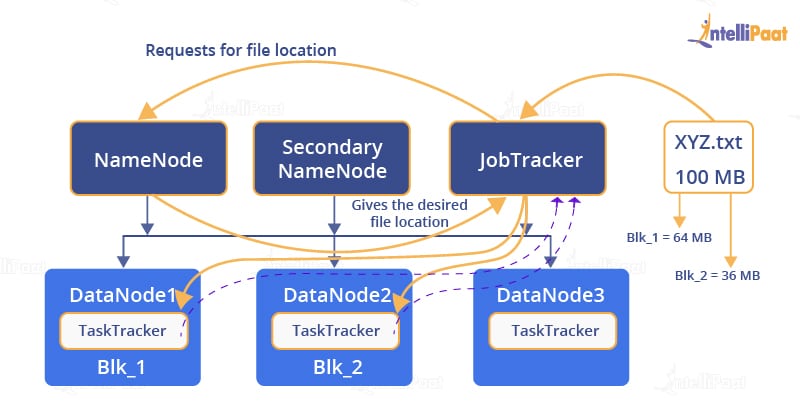
Finally, the JobTracker will collect the data and send it back to the requested source.
How does Yahoo! use Hadoop Architecture?
In Yahoo!, there are 36 different Hadoop clusters that are spread across Apache HBase, Storm, and YARN, i.e., there are 60,000 servers in total made from 100s of distinct hardware configurations. Yahoo! runs the largest multi-tenant Hadoop installation in the world.
There are approximately 850,000 Hadoop jobs daily, which are run by Yahoo!.
The cost of storing and processing data using Hadoop is the best way to determine whether Hadoop is the right choice for your company. When comparing on the basis of the expense for managing data, Hadoop is much cheaper than any legacy systems.
The cost of storing and processing data using Hadoop is the best way to determine whether Hadoop is the right choice for your company. When comparing on the basis of the expense for managing data, Hadoop is much cheaper than any legacy systems.
In this section of the Hadoop tutorial, we learned about the two layers present in the Hadoop architecture. We also saw how Yahoo! uses Hadoop architecture.
Now that we have seen the robust architecture of Hadoop, let’s move on with our next section of the tutorial, i.e., Hadoop installation.

No comments:
Post a Comment