- SQL CTE (common table expression) offers us a tool to group and order data in SQL Server, we will see an applied example of using common table expressions to solve the business challenge of re-basing identifier columns.
- We can think of the business problem like the following: we have a table of foods that we sell with a unique identifier integer associated with the food. As we sell new foods, we insert the food in our list. After a few years, we observe that many of our queries involve the foods grouped alphabetically.
- However, our food list is just a list of foods that we add to as needed without any grouping. Rather than re-group or re-order through queries using a SQL CTE or subquery, we want to permanently update the identifier.
Because we prefer to use SARGable operators, grouping related items may be a task that will help some of our queries. One way we can solve this is by adding a new grouping field and using it. However, if we’re required to re-base our identifier, adding a new column will only be part of the solution.
Our example data set
For this tip, we’ll be solving this problem using the below example tables with organic foods and an orders table that holds orders from our organic foods table. To provide an extra check, I’ve organized the orders table where every order purchased 2 items and orders are either vegetable or fruit orders. This helps as another check as we work through the problem. We can use this same re-base technique involving common table expressions with any other set of tables where we’re required to re-base an identifier field with some considerations about how our tables are organized:
- If we are using foreign key references that are part of the identifier that is being re-based, we must first remove the foreign keys before we proceed. The same applies to other constraints
- Since we’re looking at identifiers, this means that primary keys will be involved in at least one table’s re-basement, which affects dependencies, such as replication, auditing, etc. We must first solve these dependencies before proceeding
For populating our experiment data, we’ll execute the below code and review:
CREATE TABLE tbOrganicFoodsList(
OrganicFoodId SMALLINT NOT NULL,
OrganicFood VARCHAR(50) NOT NULL
)
ALTER TABLE tbOrganicFoodsList ADD CONSTRAINT PK_OrganicFoodId_List PRIMARY KEY CLUSTERED (OrganicFoodId)
INSERT INTO tbOrganicFoodsList
VALUES (1,'Broccoli')
, (2,'Apple')
, (3,'Fig')
, (4,'Potato')
, (5,'Kale')
, (6,'Cucumber')
CREATE TABLE tbOrganicFoodOrders (
OrderId INT NOT NULL,
OrganicFoodId SMALLINT NOT NULL
)
ALTER TABLE tbOrganicFoodOrders ADD CONSTRAINT FK_OrganicFoodId_Orders FOREIGN KEY (OrganicFoodId) REFERENCES tbOrganicFoodsList (OrganicFoodId)
INSERT INTO tbOrganicFoodOrders
VALUES (1,2)
, (1,3)
, (2,1)
, (2,5)
, (3,6)
, (3,1)
, (4,5)
, (4,6)
, (5,3)
, (5,2)
|
Rebasing an identity with Common table expressions
One principle in math is to show every step and to make this understandable, we will be doing this in this tip with the help of SQL CTEs, especially with ordering data before we rebase data.
We will add one column to our tbOrganicFoodsList table and one column to our tbOrganicFoodOrders table. If we have any dependencies on our primary or foreign keys here, we would first either remove them (drop and re-create script for later) or disable them. Our next step will be dropping the foreign key and then the primary key.
ALTER TABLE tbOrganicFoodOrders DROP CONSTRAINT FK_OrganicFoodId_Orders
ALTER TABLE tbOrganicFoodsList DROP CONSTRAINT PK_OrganicFoodId_List
|
Now that we’ve removed our constraints, we’ll begin by adding a column to our tbOrganicFoodsList that will save our identifier field before we re-base it.
This will help us avoid column re-naming by creating a new column that’s organized, dropping the old column, and then renaming our new column. That is also an acceptable way to solve this challenge.
ALTER TABLE tbOrganicFoodsList ADD OldId SMALLINT
UPDATE tbOrganicFoodsList
SET OldId = OrganicFoodId
SELECT *
FROM tbOrganicFoodsList
|
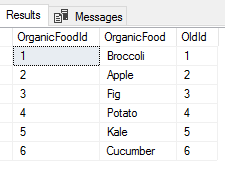
Our food list with the new column added that we’ll use as a reference.
Using a Common table expression named UpdateOrder, in the below code we order the foods alphabetically in our UpdateOrder CTE and call it an UpdateId as well as select our OrganicFoodId, which we’ll be updating to this new order. From our select statement, we can see the new order of our OrganicFoodId versus the OldId.
This is a key step if we have old archives on disk backup files or other servers, as this table will allow us to compare the data from our re-based data to our original data, assuming we don’t rebase archived data. Because of this reason, we’ll notice that we save a copy of this table in this step – the saved data is RebasedDataKey_tbOrganicFoodsList.
;WITH UpdateOrder AS(
SELECT ROW_NUMBER() OVER (ORDER BY OrganicFood ASC) UpdateId --- orders foods alphabetically
, OrganicFoodId
FROM tbOrganicFoodsList
)
UPDATE UpdateOrder
SET OrganicFoodId = UpdateId
SELECT *
FROM tbOrganicFoodsList
ORDER BY OrganicFoodId
---- Saved re-basement data
SELECT * INTO RebasedDataKey_tbOrganicFoodsList FROM tbOrganicFoodsList
|
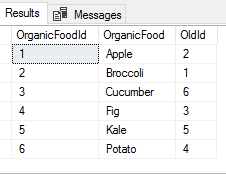
Now, our OrganicFoodId is ordered alphabetically and we see the old order.
In our next step, we’ll look at our tables joined and see the results of the OrganicFoodId and OldId with the orders that we’ll be using to create a SQL CTE to update the food list. Since I intentionally grouped the orders so that we could perform a quick check, we can see how the new OrganicFoodId that’s been re-based will appear on the tbOrganicFoodOrders table.
From here, we use the same join and only select the two OrganicFoodId columns – one from the table we’ve re-based (tbOrganicFoodsList) and the other from the table we’ll be updating (tbOrganicFoodOrders).
To make this clear, I’ve titled the column in the SQL CTE to what they’ll be used for – one needs to be re-based (NeedsRebase) and it will be updated and the other is the base which will be the reference point for the update. We then see the update run against this CTE in SQL Server, which updates the appropriate rows of the tbOrganicFoodOrders table.
SELECT *
FROM tbOrganicFoodsList t
INNER JOIN tbOrganicFoodOrders t2 ON t.OldId = t2.OrganicFoodId
;WITH UpdateBase AS(
SELECT
t2.OrganicFoodId OrganicFoodId_NeedsRebase
, t.OrganicFoodId OrganicFoodId_Base
FROM tbOrganicFoodsList t
INNER JOIN tbOrganicFoodOrders t2 ON t.OldId = t2.OrganicFoodId
)
UPDATE UpdateBase
SET OrganicFoodId_NeedsRebase = OrganicFoodId_Base
|
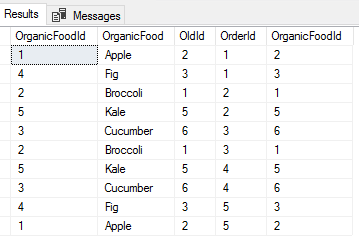
We see the order in our query and we also see how naming in the SQL CTE makes it easy to run an update.
SELECT
t2.OrderId
, t2.OrganicFoodId
, t.OrganicFood
FROM tbOrganicFoodsList t
INNER JOIN tbOrganicFoodOrders t2 ON t.OrganicFoodId = t2.OrganicFoodId
|
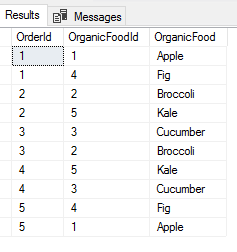
Our orders with the new order in place.
Our final step is to remove the OldId column and add our primary key and foreign key constraints:
ALTER TABLE tbOrganicFoodsList DROP COLUMN OldId
ALTER TABLE tbOrganicFoodsList ADD CONSTRAINT PK_OrganicFoodId_List PRIMARY KEY CLUSTERED (OrganicFoodId)
ALTER TABLE tbOrganicFoodOrders ADD CONSTRAINT FK_OrganicFoodId_Orders FOREIGN KEY (OrganicFoodId) REFERENCES tbOrganicFoodsList (OrganicFoodId)
|
Some considerations
- What if we wanted to group the items alphabetically within a category, like alphabetical list of vegetables, fruits, etc? We’d take the same logic only we’d partition it further by more detailed groups. As we’ve seen with CTEs in SQL Server, these make it easy to organize data and work intuitively to update columns from new columns or new designs
- Since it’s impossible to have all information up front, on the initial design of our tables a best practice to avoid this problem is to consider the columns that will be used in queries and how much space should be allowed between these values. Using the same example with a food list, for each group, we may want up to 10000 or more of range values for each category, even if we only use a fraction of those values. We can apply math operations to SQL CTE order, such as the following creating a grouping identifier on sys.tables:
;WITH PartitionTables AS(
SELECT
DENSE_RANK() OVER (ORDER BY is_ms_shipped) PlusId
, (ROW_NUMBER() OVER (PARTITION BY is_ms_shipped ORDER BY [name])) Id
, (DENSE_RANK() OVER (ORDER BY is_ms_shipped)*1000) + (ROW_NUMBER() OVER (PARTITION BY is_ms_shipped ORDER BY [name])) GroupId
, is_ms_shipped
FROM sys.tables
)
SELECT *
FROM PartitionTables
|
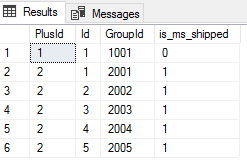
We have two groups of tables – MS shipped and non-MS shipped and notice our GroupId range of 1000 tables between them.
- Of the steps required, the most manual will be re-basing the primary table, as our re-basement is determined by how we want to group: alphabetically, by category or status, by range, etc. For instance, if we had 1000 foods and wanted to group them by color, the step of grouping would be manual to get our table with the new grouping. Unfortunately, SQL CTEs and subqueries can’t help us for custom grouping, but once we have them, we can use them to assist with ordering other tables. From there, we would follow the same plug-and-play pattern of updates of the identifier fields through joins on the old identifier field

No comments:
Post a Comment